






撰寫本文時,Bun 擁有超過 2,600 個未解決的 GitHub issue。我們很感謝使用者和他們的回饋,但有些 issue 真的難以重現和除錯。
應用程式和 SaaS 產品可以使用像 Sentry 這樣絕佳的錯誤回報服務,但對於像 Bun 這樣的 CLI 工具來說,上傳核心轉儲檔案在隱私、效能和可執行檔大小方面有著更難以合理化的權衡取捨。
這就是為什麼在 Bun v1.1.5 版本中,我為 Zig 和 C++ 錯誤回報寫了一個精簡的新格式。錯誤回報可以放進約 150 位元組的 URL 中,且不包含任何個人資訊。
為什麼不直接使用作業系統的錯誤回報工具?
有些作業系統,像是 macOS,有內建的錯誤回報工具,但這通常意味著需要將除錯符號與應用程式一起發布。對於 Linux 來說,這些除錯符號約為 30 MB,而 macOS 約為 9 MB。
du -h ./bun60M ./bunllvm-strip bundu -h ./bun51M ./bun而在 Windows 上,.pdb 檔案超過 250 MB
(gi bun.pdb).Length / 1mb252.4492187530 MB 到 250 MB 是個非常龐大的檔案大小,若要加到每個 Bun 的安裝檔中。
但如果沒有除錯符號,錯誤回報的功能就會非常有限。而且在混合了位址空間配置隨機化 (Address space layout randomization, ASLR) 的情況下,所有的函式位址都會變得無用。
uh-oh: reached unreachable code
bun will crash now 😭😭😭
----- bun meta -----
Bun v1.1.0 (5903a614) Windows x64
AutoCommand:
Builtins: "bun:main"
Elapsed: 27ms | User: 0ms | Sys: 0ms
RSS: 91.69MB | Peak: 91.69MB | Commit: 0.14GB | Faults: 22579
----- bun meta -----
Search GitHub issues https://bun.dev.org.tw/issues or join in #windows channel in https://bun.dev.org.tw/discord
thread 104348 panic: reached unreachable code
???:?:?: 0x7ff62a629f17 in ??? (bun.exe)
???:?:?: 0x7ff62a907a83 in ??? (bun.exe)
???:?:?: 0x7ff62a61f392 in ??? (bun.exe)
???:?:?: 0x7ff62ade7ff1 in ??? (bun.exe)
???:?:?: 0x7ff62ab2193c in ??? (bun.exe)
???:?:?: 0x7ff62ab21166 in ??? (bun.exe)
???:?:?: 0x7ff62cd3ddeb in ??? (bun.exe)
???:?:?: 0x7ff62b7a4bb6 in ??? (bun.exe)
???:?:?: 0x7ff62b7a33bd in ??? (bun.exe)
???:?:?: 0x1bab9ca115d in ??? (???)
???:?:?: 0x1bab9ca111f in ??? (???)
全新的錯誤回報工具
在 Bun v1.1.5 版本中,當發生錯誤或 panic 時,Bun 會印出像這樣的訊息
Bun v1.1.5 (0989f1a) Windows x64
Args: "C:\Users\chloe\.bun\bin\bun.exe", ".\crash.js"
Builtins: "bun:main"
Elapsed: 40ms | User: 15ms | Sys: 15ms
RSS: 92.80MB | Peak: 92.80MB | Commit: 0.14GB | Faults: 22857
panic(main thread): Internal assertion failure
oh no: Bun has crashed. This indicates a bug in Bun, not your code.
To send a redacted crash report to Bun's team,
please file a GitHub issue using the link below:
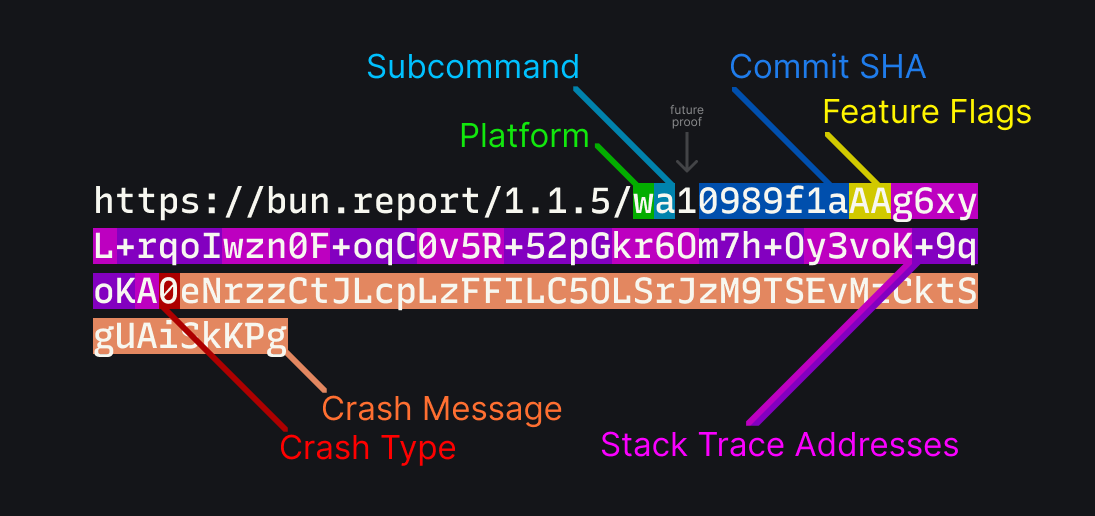
https://bun.report/1.1.5/wa10989f1aAAg6xyL+rqoIwzn0F+oqC0v5R+52pGkr6Om7h+Oy3voK+9qoKA0eNrzzCtJLcpLzFFILC5OLSrJzM9TSEvMzCktSgUAiSkKPg
這個 bun.report 連結,當被點擊時,會重新導向至開啟一個預先填寫好的 GitHub issue 表單,並將重新對應的堆疊追蹤編碼在 URL 中。
讓位址變得有用
函式位址是指向記憶體中應用程式碼載入位置的指標,為了安全起見,其中包含隨機化的偏移量。這表示如果我們嘗試對其進行反組譯,將一無所獲。
llvm-symbolizer --exe ./bun.pdb 0x7ff62a629f17 0x7ff62a907a83??
??:0:0訣竅是簡單地從二進制檔案的基底位址減去該位址。
pub fn getRelativeAddress(address: usize) ?usize {
const module = getModuleFromAddress(address) orelse {
// Could not resolve address! This can be hit for some
// Windows internals, as well as JIT'd JavaScript.
return null;
};
return address - module.base_address;
}
實際上,這個函式複雜得多,因為每個平台都有不同的 API。
注意 – 我上面提到的「模組」(module) 僅適用於 Windows。在 macOS 上稱為「映像檔」(image),而在 Linux 上稱為「共享物件」(shared object)。它們都指向記憶體中已載入的函式庫或可執行檔的相同概念。為了簡潔起見,我將繼續將它們稱為「模組」。
- Windows:呼叫
GetModuleHandleExW並使用GET_MODULE_HANDLE_EX_FLAG_FROM_ADDRESS旗標。基底位址是模組的指標。 - Linux:使用
dl_iterate_phdr迭代已載入的模組,一旦找到包含原始位址的模組,dl_phdr_info結構上的.dlpi_addr將會是基底位址。 - macOS:可以使用
_dyld_image_count和_dyld_get_image_header函式來迭代模組,然後_dyld_get_image_vmaddr_slide取得 ASLR 滑動值。- 產生的位址仍然包含映像檔的偏移量 (對於 Bun 來說,它是
0x100000000,可以使用image list在 lldb 中列出這些資訊)。為了編碼更短的 URL,這個偏移量會被移除,但在重新對應之前必須重新加上,否則llvm-symbolizer將會失敗。
- 產生的位址仍然包含映像檔的偏移量 (對於 Bun 來說,它是
對於 Linux 和 MacOS 來說,第一個模組指的是主要的應用程式二進制檔案。在 Windows 上,您可以將模組的名稱與 peb.ProcessParameters.ImagePathName 進行比較,以判斷它是否為主要二進制檔案。
通常,一旦模組和相對位址被解析,應用程式會立即開啟除錯符號並反組譯函式。為了避免下載和解析除錯符號的成本,我們將反組譯的工作卸載到伺服器。這個伺服器可以快取所有的除錯符號,並在幾秒鐘內反組譯堆疊追蹤。同時,它也可以作為開啟新 GitHub issue 的連結。
bun.report 的 URL 結構
讓我們再次看看這個 URL,並分解它是如何被編碼的
- 平台:單一字元,表示平台。
w代表 x86_64 Windows,M代表 aarch64 macOS,以及等等。 - 子命令:單一字元,表示子命令,例如
bun test、bun install或bun run。 - Commit SHA:目前 Bun 版本的 commit SHA。這用於稍後獲取除錯符號。
- 功能旗標:指示 Bun 崩潰前使用了哪些 API 和功能。
- 堆疊追蹤位址:先前計算的位址。
- 錯誤類型:單一字元,表示錯誤類型。
- 錯誤訊息:來自錯誤的訊息,其格式取決於類型。
注意 – URL 中的版本號碼實際上只是為了展示。這是為了讓僅憑上述資訊,人們就可以手動分析出很多關於錯誤的資訊。例如,您可以通過 w 平台識別符快速識別出 Windows 錯誤。更深入地說,您可以通過在字串末尾附近尋找 A2 來識別分段錯誤。
VLQ 真有趣
為了讓 URL 保持在合理長度內,堆疊追蹤位址使用 base64 可變長度數量 (Variable Length Quantity, VLQ) 數字進行編碼。這樣可以讓小數字用較少的字元進行編碼,同時仍然能夠編碼大數字。這與 JavaScript 原始碼地圖中用於儲存行號的技術相同。
轉換看起來像這樣。請注意 VLQ 如何將較小的位址編碼為較小的數字。
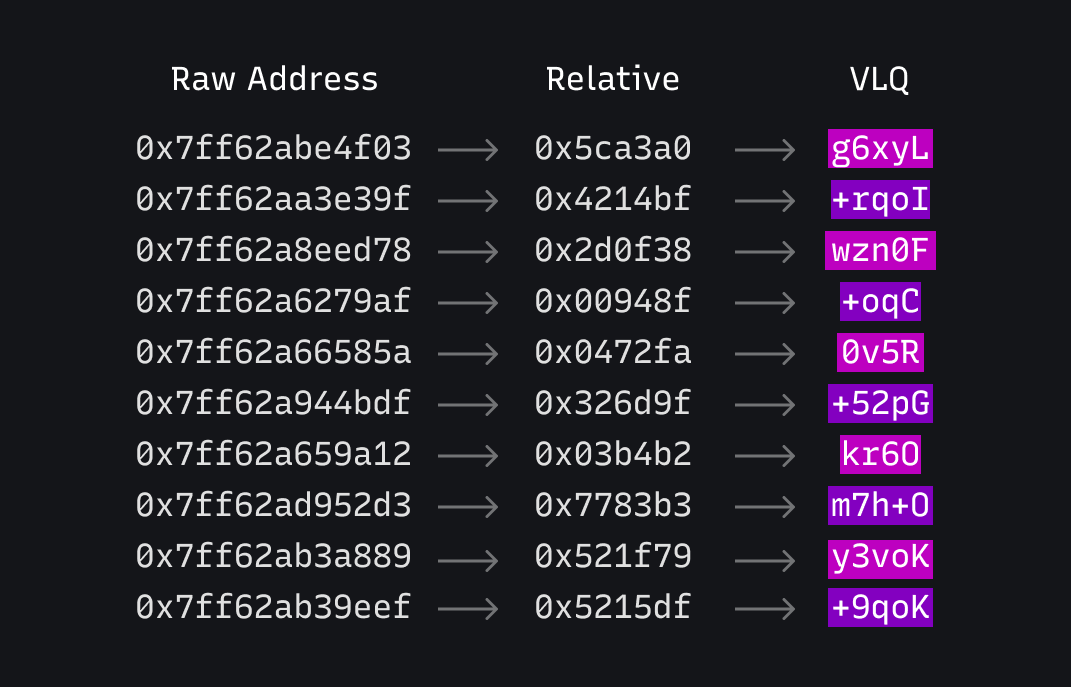
伺服器可以將這些解碼回相對位址、使用 commit hash 和平台下載除錯符號,並使用 llvm-symbolizer 反組譯函式名稱。
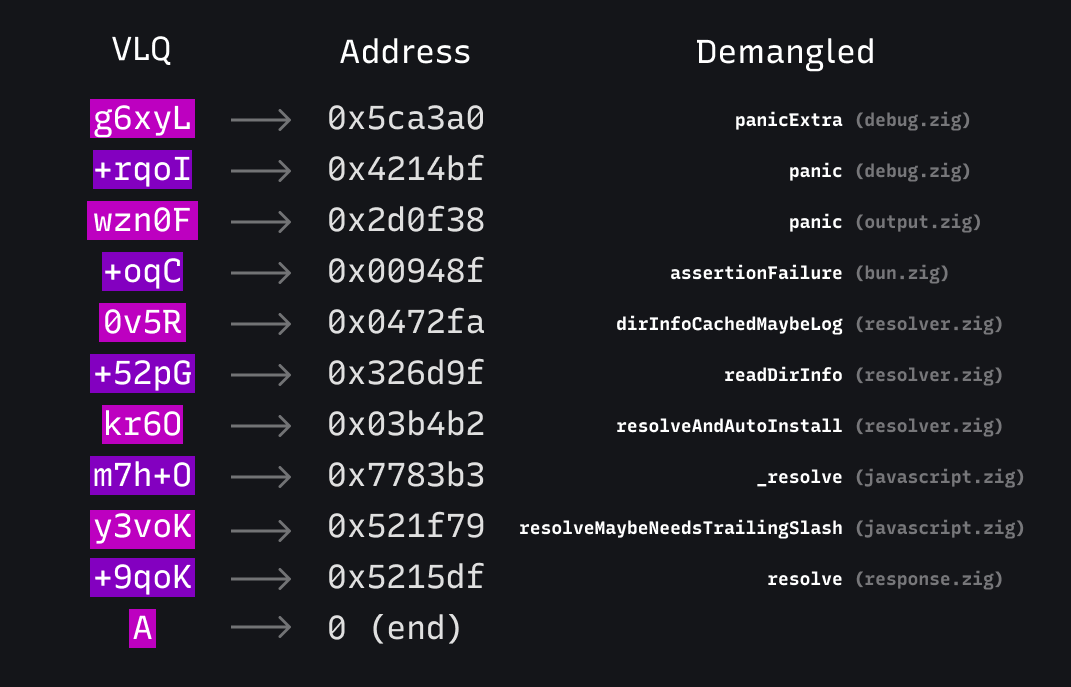
現在很明顯發生了什麼事:dirInfoCachedMaybeLog 中觸發了一個斷言,這來自 Windows 上模組解析器程式碼的一部分。
什麼是「功能」(Features)?
URL 也會編碼一個 64 位元整數,其中每個位元對應於是否使用了 Bun 中的特定功能。這些旗標提示了哪些 API 和系統可能導致了錯誤。例如,當自動載入任何 .env 檔案時,會設定 dotenv 功能;當使用 fetch() 時,會設定 fetch 功能,依此類推。(完整列表)
Zig 的編譯時期元編程讓建立這個位元欄位變得容易。我們已經有一個用於追蹤功能的全域變數容器。
pub const Features = struct {
pub var bunfig: usize = 0;
pub var http_server: usize = 0;
pub var shell: usize = 0;
pub var spawn: usize = 0;
pub var macros: usize = 0;
// ... and so on
};
在各種 API 內部,我們會遞增這些數字以標記功能的使用情況。
為了將這些編碼成單一的 u64 整數,我們可以使用 std.meta 來迭代功能列表並建立一個列表。
pub const feature_list = brk: {
const decls = std.meta.declarations(Features);
var names: [decls.len][:0]const u8 = undefined;
var i = 0;
for (decls) |decl| {
if (@TypeOf(@field(Features, decl.name)) == usize) {
names[i] = decl.name;
i += 1;
}
}
const names_const = names[0..i].*;
break :brk names_const;
};
然後,可以動態派生一個 packed struct,以使用每個功能一位元。這個結構的功能類似於整數,但互動方式類似於 struct。
// note: some fields omitted for brevity
pub const PackedFeatures = @Type(.{
.Struct = .{
.layout = .@"packed",
.backing_integer = u64,
.fields = brk: {
var fields: [64]StructField = undefined;
for (feature_list, 0..) |name, i| {
fields[i] = .{ .name = name, .type = bool };
}
fields[feature_list.len] = .{
.name = "__padding",
.type = @Type(.{ .Int = .{ .bits = 64 - feature_list.len } }),
};
break :brk fields[0..feature_list.len + 1];
},
},
});
最後,當 Bun 崩潰時,可以使用 inline for 非常簡單地建構位元欄位,inline for 是一種在編譯時期迭代某些內容,但在運行時執行內部內容的方式。
pub fn packedFeatures() PackedFeatures {
var bits = PackedFeatures{};
inline for (feature_list) |name| {
if (@field(Features, name) > 0) {
@field(bits, name) = true;
}
}
return bits;
}
現在,將新功能添加到原始的 Features 結構中,將在錯誤回報工具中正確處理它,而無需重複我們自己。
使用 C 或 Rust 的巨集也可以做到這類事情,但我認為使用 Zig comptime 會更簡單且更易讀。
這與核心轉儲檔案相比如何?
核心轉儲檔案包含更多資訊,但它們非常龐大,需要除錯符號才能發揮作用,並且包含許多潛在的敏感或機密資訊。
我們希望避免在報告中發送任何 JavaScript/TypeScript 原始碼、環境變數或其他敏感資訊的可能性。這就是為什麼我們只發送 Zig/C++ 堆疊追蹤和一些其他細節。這種方法不是預設發送所有內容,而是僅發送我們(可能)需要診斷 issue 的內容。如果我們需要更多資訊,我們可以要求使用者提供,但這比之前一堆未對應的位址的虛無要好得多。
Demo
為了將所有內容整合在一起,我寫了一個小型網頁應用程式,讓您可以測試錯誤回報工具,該工具可以在首頁 bun.report 上找到。如果您在任何錯誤回報 URL 的末尾加上 /view,也會到達這裡。
Bun 正在舊金山招聘
如果您對從事像這樣的專案感興趣,我們正在舊金山招聘工程師!我們正在尋找系統工程師來協助建構 JavaScript 的未來。 在此申請